
Membangun model machine learning saja tidaklah cukup, kita perlu mengetahui seberapa baik model kita bekerja. Tentunya, dengan sebuah ukuran (atau istilah yang seringkali digunakan adalah metric).
Evaluation metrics sangatlah banyak dan beragam, namun untuk tulisan ini, saya hanya akan fokus dengan evaluation metrics yang paling umum digunakan untuk model klasifikasi. Ya, precision, recall dan F1-Score.
Alasan saya hanya membahas ketiganya, karena buat saya, mereka dapat memperlihatkan bagaimana model kita mengambil suatu keputusan di dunia nyata, bisa dari urusan bisnis, sampai melakukan diagnosa medis.
Namun, kita tidak dapat membicarakan precision, recall dan F1-Score. Sebelum memperkenalkan ke kalian, suatu matriks yang seringkali membingungkan banyak orang, yaitu Confusion Matrix.
Dalam mengevaluasi performance algoritma dari Machine Learning (ML) (khususnya supervised learning), kita menggunakan acuan Confusion Matrix. Confusion Matrix merepresentasikan prediksi dan kondisi sebenarnya(aktual) dari data yang dihasilkan oleh algoritma ML. Berdasarkan Confusion Matrix, kita bisa menentukan Accuracy, Precission, Recall dan Specificity.
Confusion Matrix
Jangan khawatir dengan matematiknya, itu tidak membingungkan. Tapi yang membingungkan adalah terminologinya. Sebelum lebih jauh, ada baiknya jika saya tekankan, yang akan saya bicarakan ini, untuk masalah binary classification.
Begini bentuk Confusion Matrix:
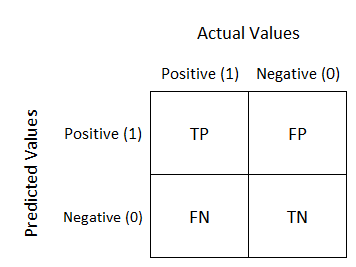
0 untuk Label Negatif dan 1 untuk Label Positif. Confusion Matrix punya empat istilah:
- True Negative (TN): Model memprediksi data ada di kelas Negatif dan yang sebenarnya data memang ada di kelas Negatif.
- True Postive (TP): Model memprediksi data ada di kelas Positif dan yang sebenarnya data memang ada di kelas Positif.
- False Negative (FN): Model memprediksi data ada di kelas Negatif, namun yang sebenarnya data ada di kelas Positif.
- False Positive (FP): Model memprediksi data ada di kelas Positif, namun yang sebenarnya data ada di kelas Negatif.
Saya menggunakan contoh kasus prediksi mahasiswa Drop Out (DO) untuk memudahkan memahami Accuracy, Precision, Recall dan Specificity
Studi Kasus Prediksi Mahasiswa DO
Dalam sebuah project yang menggunakan algoritma ML, memprediksi apakah mahasiswa berpotensi DO atau tidak. Setelah algoritma tersebut dijalankan (dalam bentuk program), hasilnya adalah seperti berikut ini:
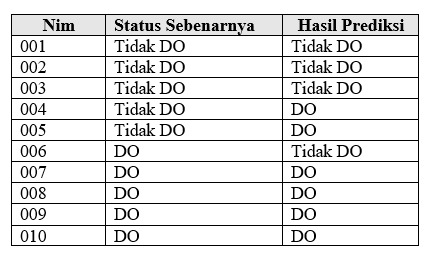
Dari hasil prediksi di atas, hanya ada kemungkinan 4 kasus yang terjadi:
- True Positive (TP) : kasus dimana mahasiswa diprediksi (Positif) DO, memang benar(True) DO. Dalam contoh di atas adalah 4 mahasiswa dengan NIM 007, 008, 009, 010. Jadi nilai TP nya adalah 4
- True Negative (TN) : kasus dimana mahasiswa diprediksi tidak(Negatif) DO dan sebenarnya mahasiswa tersebut memang (True) tidak DO. Dalam contoh di atas terjadi pada mahasiswa 001, 002, dan 003. Jadi TN nya adalah 3
- False Positve (FP) : kasus dimana mahasiswa yang diprediksi positif DO, ternyata tidak DO. Prediksinya salah (False). Dalam contoh di atas terjadi pada mahasiswa 004 dan 005. Jadi nilai FP adalah 2
- False Negatif (FN): kasus dimana mahasiswa yang diprediksi tidak DO (Negatif), tetapi ternyata sebenarnya(TRUE) DO. Dalam contoh kasus di atas terjadi pada mahasiswa 010. jadi FN = 1
Cara mudah untuk mengingatnya adalah :
- Jika diawali dengan TRUE maka prediksinya benar, entah diprediksi terjadi atau tidak terjadi. Dalam kasus di atas, entah diprediksi DO atau Tidak DO, data sebenarnya adalah seperti itu.
- Jika diawali dengan FALSE maka menyatakan prediksinya salah
- Positif dan Negatif merupakan hasil prediksi dari program.
Pengukuran Performance
Accuracy
Merupakan rasio prediksi Benar (positif dan negatif) dengan keseluruhan data. Akurasi menjawab pertanyaan “Berapa persen mahasiswa yang benar diprediksi DO dan Tidak DO dari kesuluruhan mahasiswa”
Akurasi = (TP + TN ) / (TP+FP+FN+TN)
pada contoh kasus di atas, Akurasi = (4+3) / (4+2+1+3) = 7/10 = 70%
Precission
Merupakan rasio prediksi benar positif dibandingkan dengan keseluruhan hasil yang diprediksi positf. Precission menjawab pertanyaan “Berapa persen mahasiswa yang benar DO dari keseluruhan mahasiswa yang diprediksi DO?”
Precission = (TP) / (TP+FP)
pada contoh kasus di atas, Precission = 4 / (4+2) = 4/6 = 67%.
Recall (Sensitifitas)
Merupakan rasio prediksi benar positif dibandingkan dengan keseluruhan data yang benar positif. Recall menjawab pertanyaan “Berapa persen mahasiswa yang diprediksi DO dibandingkan keseluruhan mahasiswa yang sebenarnya DO”.
Recall = (TP) / (TP + FN)
pada contoh kasus di atas Recall = 4/(4+1) = 4/5 =80%.
Specificity
Merupakan kebenaran memprediksi negatif dibandingkan dengan keseluruhan data negatif. Specificity menjawab pertanyaan “Berapa persen mahasiswa yang benar diprediksi tidak DO dibandingkan dengan keseluruhan mahasiswa yang sebenarnya tidak DO”.
Specificity = (TN)/ (TN + FP)
F1 Score
F1 Score merupakan perbandingan rata-rata presisi dan recall yang dibobotkan
F1 Score = 2 * (Recall*Precission) / (Recall + Precission)
dalam kasus di atas, F1 Score = 2* (80%*67%) / ( 80% + 67%) = 72,93%
Pemilihan acuan performansi algoritma
Nah, jika kita membandingkan beberapa algoritma ML yang berbeda dengan accuracy, precission, recall dan specificity yang berbeda-beda, algoritma mana yang kita pilih? Apa yang digunakan acuan?
Pilih algoritma yang memiliki Accuracy tinggi jika
Akurasi sangat bagus kita gunakan sebagai acuan performansi algoritma JIKA dataset kita memiliki jumlah data False Negatif dan False Positif yang sangat mendekati (Symmetric). Namun jika jumlahnya tidak mendekati, maka sebaiknya gunakan F1 Score sebagai acuan.
Pada contoh di atas, nilai FP dan FN mendekati, maka accuracy bisa digunakan sebagai acuan ukuran performansi tersebut.
Pilih algoritma yang memiliki Recall tinggi jika
kita lebih memilih False Positif lebih baik terjadi daripada False Negatif.
Dalam contoh di atas, maka kita mempertimbangkan Recall karena lebih baik algoritma kita memprediksi mahasiswa positif DO tetapi sebenarnya tidak DO daripada algoritma salah memprediksi bahwa mahasiwa diprediksi tidak DO padahal sebenarnya dia DO.
Pilih algoritma yang memiliki Precission tinggi jika
kita lebih menginginkan terjadinya True Positif dan sangat tidak menginginkan terjadinya False Positif. Contohnya adalah pada kasus klasifikasi email SPAM atau tidak. Kita lebih memilih jika email yang sebenarnya SPAM namun diprediksi tidak SPAM (sehingga tetap ada pada kotak masuk email kita), daripada email yang sebenarnya bukan SPAM tapi diprediksi SPAM (sehingga tidak ada pada kotak masuk kita)
Pilih algoritma yang memiliki Specificity tinggi jika
kita tidak menginginkan terjadinya false positif. Contohnya pada prediksi apakah seseorang kecanduan narkoba atau tidak maka kita sangat mengharapkan tidak terjadi salah mendeteksi orang yang sebenarnya negatif tapi dinyatakan positif. Kasihan dia masuk penjara padahal tidak kecanduan narkoba :-)
Referensi :
https://stevkarta.medium.com/membicarakan-precision-recall-dan-f1-score-e96d81910354







Comments 0
Loading comments...